

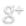


Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
|
1 2 3 4 |
<span class="hljs-meta">>>> </span>my_series.index RangeIndex(start=<span class="hljs-number">0</span>, stop=<span class="hljs-number">6</span>, step=<span class="hljs-number">1</span>) <span class="hljs-meta">>>> </span>my_series.values array([ <span class="hljs-number">5</span>, <span class="hljs-number">6</span>, <span class="hljs-number">7</span>, <span class="hljs-number">8</span>, <span class="hljs-number">9</span>, <span class="hljs-number">10</span>], dtype=int64) |
Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
|
1 2 3 |
<span class="hljs-meta">>>> </span>my_series[<span class="hljs-number">4</span>] <span class="hljs-number">9</span> |
Индексы можно задавать явно:
|
1 2 3 4 |
<span class="hljs-meta">>>> </span>my_series2 = pd.Series([<span class="hljs-number">5</span>, <span class="hljs-number">6</span>, <span class="hljs-number">7</span>, <span class="hljs-number">8</span>, <span class="hljs-number">9</span>, <span class="hljs-number">10</span>], index=[<span class="hljs-string">'a'</span>, <span class="hljs-string">'b'</span>, <span class="hljs-string">'c'</span>, <span class="hljs-string">'d'</span>, <span class="hljs-string">'e'</span>, <span class="hljs-string">'f'</span>]) <span class="hljs-meta">>>> </span>my_series2[<span class="hljs-string">'f'</span>] <span class="hljs-number">10</span> |
Делать выборку по нескольким индексам и осуществлять групповое присваивание:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<span class="hljs-meta">>>> </span>my_series2[[<span class="hljs-string">'a'</span>, <span class="hljs-string">'b'</span>, <span class="hljs-string">'f'</span>]] a <span class="hljs-number">5</span> b <span class="hljs-number">6</span> f <span class="hljs-number">10</span> dtype: int64 <span class="hljs-meta">>>> </span>my_series2[[<span class="hljs-string">'a'</span>, <span class="hljs-string">'b'</span>, <span class="hljs-string">'f'</span>]] = <span class="hljs-number">0</span> <span class="hljs-meta">>>> </span>my_series2 a <span class="hljs-number">0</span> b <span class="hljs-number">0</span> c <span class="hljs-number">7</span> d <span class="hljs-number">8</span> e <span class="hljs-number">9</span> f <span class="hljs-number">0</span> dtype: int64 |
Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class="hljs-meta">>>> </span>my_series2[my_series2 > <span class="hljs-number">0</span>] c <span class="hljs-number">7</span> d <span class="hljs-number">8</span> e <span class="hljs-number">9</span> dtype: int64 <span class="hljs-meta">>>> </span>my_series2[my_series2 > <span class="hljs-number">0</span>] * <span class="hljs-number">2</span> c <span class="hljs-number">14</span> d <span class="hljs-number">16</span> e <span class="hljs-number">18</span> dtype: int64 |
Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
|
1 2 3 4 5 6 7 8 9 10 |
<span class="hljs-meta">>>> </span>my_series3 = pd.Series({<span class="hljs-string">'a'</span>: <span class="hljs-number">5</span>, <span class="hljs-string">'b'</span>: <span class="hljs-number">6</span>, <span class="hljs-string">'c'</span>: <span class="hljs-number">7</span>, <span class="hljs-string">'d'</span>: <span class="hljs-number">8</span>}) <span class="hljs-meta">>>> </span>my_series3 a <span class="hljs-number">5</span> b <span class="hljs-number">6</span> c <span class="hljs-number">7</span> d <span class="hljs-number">8</span> dtype: int64 <span class="hljs-meta">>>> </span><span class="hljs-string">'d'</span> <span class="hljs-keyword">in</span> my_series3 <span class="hljs-keyword">True</span> |
У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
|
1 2 3 4 5 6 7 8 9 10 |
<span class="hljs-meta">>>> </span>my_series3.name = <span class="hljs-string">'numbers'</span> <span class="hljs-meta">>>> </span>my_series3.index.name = <span class="hljs-string">'letters'</span> <span class="hljs-meta">>>> </span>my_series3 letters a <span class="hljs-number">5</span> b <span class="hljs-number">6</span> c <span class="hljs-number">7</span> d <span class="hljs-number">8</span> Name: numbers, dtype: int64 |
Индекс можно поменять “на лету”, присвоив список атрибуту index объекта Series
|
1 2 3 4 5 6 7 8 |
<span class="hljs-meta">>>> </span>my_series3.index = [<span class="hljs-string">'A'</span>, <span class="hljs-string">'B'</span>, <span class="hljs-string">'C'</span>, <span class="hljs-string">'D'</span>] <span class="hljs-meta">>>> </span>my_series3 A <span class="hljs-number">5</span> B <span class="hljs-number">6</span> C <span class="hljs-number">7</span> D <span class="hljs-number">8</span> Name: numbers, dtype: int64 |
Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class="hljs-meta">>>> </span>df = pd.DataFrame({ <span class="hljs-meta">... </span> <span class="hljs-string">'country'</span>: [<span class="hljs-string">'Kazakhstan'</span>, <span class="hljs-string">'Russia'</span>, <span class="hljs-string">'Belarus'</span>, <span class="hljs-string">'Ukraine'</span>], <span class="hljs-meta">... </span> <span class="hljs-string">'population'</span>: [<span class="hljs-number">17.04</span>, <span class="hljs-number">143.5</span>, <span class="hljs-number">9.5</span>, <span class="hljs-number">45.5</span>], <span class="hljs-meta">... </span> <span class="hljs-string">'square'</span>: [<span class="hljs-number">2724902</span>, <span class="hljs-number">17125191</span>, <span class="hljs-number">207600</span>, <span class="hljs-number">603628</span>] <span class="hljs-meta">... </span>}) <span class="hljs-meta">>>> </span>df country population square <span class="hljs-number">0</span> Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> <span class="hljs-number">1</span> Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> <span class="hljs-number">2</span> Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> <span class="hljs-number">3</span> Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> |
Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
|
1 2 3 4 5 6 7 8 9 10 |
<span class="hljs-meta">>>> </span>df[<span class="hljs-string">'country'</span>] <span class="hljs-number">0</span> Kazakhstan <span class="hljs-number">1</span> Russia <span class="hljs-number">2</span> Belarus <span class="hljs-number">3</span> Ukraine Name: country, dtype: object <span class="hljs-meta">>>> </span>type(df[<span class="hljs-string">'country'</span>]) <<span class="hljs-class"><span class="hljs-keyword">class</span> '<span class="hljs-title">pandas</span>.<span class="hljs-title">core</span>.<span class="hljs-title">series</span>.<span class="hljs-title">Series</span>'> </span> |
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
|
1 2 3 4 5 |
<span class="hljs-meta">>>> </span>df.columns Index([<span class="hljs-string">u'country'</span>, <span class="hljs-string">u'population'</span>, <span class="hljs-string">u'square'</span>], dtype=<span class="hljs-string">'object'</span>) <span class="hljs-meta">>>> </span>df.index RangeIndex(start=<span class="hljs-number">0</span>, stop=<span class="hljs-number">4</span>, step=<span class="hljs-number">1</span>) |
В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или “на лету”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
<span class="hljs-meta">>>> </span>df = pd.DataFrame({ <span class="hljs-meta">... </span> <span class="hljs-string">'country'</span>: [<span class="hljs-string">'Kazakhstan'</span>, <span class="hljs-string">'Russia'</span>, <span class="hljs-string">'Belarus'</span>, <span class="hljs-string">'Ukraine'</span>], <span class="hljs-meta">... </span> <span class="hljs-string">'population'</span>: [<span class="hljs-number">17.04</span>, <span class="hljs-number">143.5</span>, <span class="hljs-number">9.5</span>, <span class="hljs-number">45.5</span>], <span class="hljs-meta">... </span> <span class="hljs-string">'square'</span>: [<span class="hljs-number">2724902</span>, <span class="hljs-number">17125191</span>, <span class="hljs-number">207600</span>, <span class="hljs-number">603628</span>] <span class="hljs-meta">... </span>}, index=[<span class="hljs-string">'KZ'</span>, <span class="hljs-string">'RU'</span>, <span class="hljs-string">'BY'</span>, <span class="hljs-string">'UA'</span>]) <span class="hljs-meta">>>> </span>df country population square KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> <span class="hljs-meta">>>> </span>df.index = [<span class="hljs-string">'KZ'</span>, <span class="hljs-string">'RU'</span>, <span class="hljs-string">'BY'</span>, <span class="hljs-string">'UA'</span>] <span class="hljs-meta">>>> </span>df.index.name = <span class="hljs-string">'Country Code'</span> <span class="hljs-meta">>>> </span>df country population square Country Code KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> |
Как видно, индексу было задано имя – Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
|
1 2 3 4 5 6 7 8 |
<span class="hljs-meta">>>> </span>df[<span class="hljs-string">'country'</span>] Country Code KZ Kazakhstan RU Russia BY Belarus UA Ukraine Name: country, dtype: object |
Доступ к строкам по индексу возможен несколькими способами:
- .loc – используется для доступа по строковой метке
- .iloc – используется для доступа по числовому значению (начиная от 0)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class="hljs-meta">>>> </span>df.loc[<span class="hljs-string">'KZ'</span>] country Kazakhstan population <span class="hljs-number">17.04</span> square <span class="hljs-number">2724902</span> Name: KZ, dtype: object <span class="hljs-meta">>>> </span>df.iloc[<span class="hljs-number">0</span>] country Kazakhstan population <span class="hljs-number">17.04</span> square <span class="hljs-number">2724902</span> Name: KZ, dtype: object |
Можно делать выборку по индексу и интересующим колонкам:
|
1 2 3 4 5 6 |
<span class="hljs-meta">>>> </span>df.loc[[<span class="hljs-string">'KZ'</span>, <span class="hljs-string">'RU'</span>], <span class="hljs-string">'population'</span>] Country Code KZ <span class="hljs-number">17.04</span> RU <span class="hljs-number">143.50</span> Name: population, dtype: float64 |
Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
|
1 2 3 4 5 6 7 |
<span class="hljs-meta">>>> </span>df.loc[<span class="hljs-string">'KZ'</span>:<span class="hljs-string">'BY'</span>, :] country population square Country Code KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> |
Фильтровать DataFrame с помощью т.н. булевых массивов:
|
1 2 3 4 5 6 7 |
<span class="hljs-meta">>>> </span>df[df.population > <span class="hljs-number">10</span>][[<span class="hljs-string">'country'</span>, <span class="hljs-string">'square'</span>]] country square Country Code KZ Kazakhstan <span class="hljs-number">2724902</span> RU Russia <span class="hljs-number">17125191</span> UA Ukraine <span class="hljs-number">603628</span> |
Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
|
1 2 3 4 5 6 7 |
<span class="hljs-meta">>>> </span>df.reset_index() Country Code country population square <span class="hljs-number">0</span> KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> <span class="hljs-number">1</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> <span class="hljs-number">2</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> <span class="hljs-number">3</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> |
pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
|
1 2 3 4 5 6 7 8 9 |
<span class="hljs-meta">>>> </span>df[<span class="hljs-string">'density'</span>] = df[<span class="hljs-string">'population'</span>] / df[<span class="hljs-string">'square'</span>] * <span class="hljs-number">1000000</span> <span class="hljs-meta">>>> </span>df country population square density Country Code KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> <span class="hljs-number">6.253436</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> <span class="hljs-number">8.379469</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> <span class="hljs-number">45.761079</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> <span class="hljs-number">75.377550</span> |
Не нравится новый столбец? Не проблема, удалим его:
|
1 2 3 4 5 6 7 8 |
<span class="hljs-meta">>>> </span>df.drop([<span class="hljs-string">'density'</span>], axis=<span class="hljs-string">'columns'</span>) country population square Country Code KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> |
Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
|
1 2 3 4 5 6 7 8 9 |
<span class="hljs-meta">>>> </span>df = df.rename(columns={<span class="hljs-string">'Country Code'</span>: <span class="hljs-string">'country_code'</span>}) <span class="hljs-meta">>>> </span>df country_code country population square <span class="hljs-number">0</span> KZ Kazakhstan <span class="hljs-number">17.04</span> <span class="hljs-number">2724902</span> <span class="hljs-number">1</span> RU Russia <span class="hljs-number">143.50</span> <span class="hljs-number">17125191</span> <span class="hljs-number">2</span> BY Belarus <span class="hljs-number">9.50</span> <span class="hljs-number">207600</span> <span class="hljs-number">3</span> UA Ukraine <span class="hljs-number">45.50</span> <span class="hljs-number">603628</span> |
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
|
1 2 3 4 5 6 |
<span class="hljs-keyword">import</span> pandas <span class="hljs-keyword">as</span> pd <span class="hljs-keyword">import</span> numpy <span class="hljs-keyword">as</span> np anime = pd.read_csv(<span class="hljs-string">'anime-recommendations-database/anime.csv'</span>) rating = pd.read_csv(<span class="hljs-string">'anime-recommendations-database/rating.csv'</span>) anime_modified = anime.set_index(<span class="hljs-string">'name'</span>) |
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding='ISO-8859–1'). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.
|
1 2 |
anime = pd.read_csv(<span class="hljs-string">'anime-recommendations-database/anime.csv'</span>) |

Загруженные CSV-данные
Существует похожая функция для загрузки данных из Excel-файлов — pd.read_excel.
▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
|
1 2 3 4 5 |
df = pd.DataFrame([[<span class="hljs-number">1</span>,<span class="hljs-string">'Bob'</span>, <span class="hljs-string">'Builder'</span>], [<span class="hljs-number">2</span>,<span class="hljs-string">'Sally'</span>, <span class="hljs-string">'Baker'</span>], [<span class="hljs-number">3</span>,<span class="hljs-string">'Scott'</span>, <span class="hljs-string">'Candle Stick Maker'</span>]], columns=[<span class="hljs-string">'id'</span>,<span class="hljs-string">'name'</span>, <span class="hljs-string">'occupation'</span>]) |

Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
|
1 2 |
anime_copy = anime.copy(deep=<span class="hljs-literal">True</span>) |

Копия датафрейма
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
|
1 2 |
rating[:<span class="hljs-number">10</span>].to_csv(<span class="hljs-string">'saved_ratings.csv'</span>, index=<span class="hljs-literal">False</span>) |
Экспортировать данные в виде Excel-файлов можно с помощью функции df.to_excel.
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
|
1 2 3 |
anime.head(<span class="hljs-number">3</span>) rating.tail(<span class="hljs-number">1</span>) |

Данные из начала датафрейма

Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция len(), которую я тут покажу, не входит в состав pandas. Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.
|
1 2 3 |
len(df) <span class="hljs-comment">#=> 3</span> |
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
|
1 2 |
len(ratings[<span class="hljs-string">'user_id'</span>].unique()) |
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
|
1 2 |
anime.info() |

Сведения о датафрейме
Есть ещё одна функция, похожая на df.info — df.dtypes. Она лишь выводит сведения о типах данных столбцов.
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
|
1 2 |
anime.describe() |

Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
|
1 2 |
anime.type.value_counts() |

Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
|
1 2 3 |
anime[<span class="hljs-string">'genre'</span>].tolist() anime[<span class="hljs-string">'genre'</span>] |

Результаты работы команды anime[‘genre’].tolist()

Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм anime_modified, так как его индексные значения выглядят интереснее.
|
1 2 |
anime_modified.index.tolist() |

Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
|
1 2 |
anime.columns.tolist() |
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
|
1 2 |
anime[<span class="hljs-string">'train set'</span>] = <span class="hljs-literal">True</span> |
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
|
1 2 |
anime[[<span class="hljs-string">'name'</span>,<span class="hljs-string">'episodes'</span>]] |

Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
|
1 2 |
anime.drop([<span class="hljs-string">'anime_id'</span>, <span class="hljs-string">'genre'</span>, <span class="hljs-string">'members'</span>], axis=<span class="hljs-number">1</span>).head() |

Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0), которая позволяет получать суммы значений из различных строк.
|
1 2 3 4 5 |
df = pd.DataFrame([[<span class="hljs-number">1</span>,<span class="hljs-string">'Bob'</span>, <span class="hljs-number">8000</span>], [<span class="hljs-number">2</span>,<span class="hljs-string">'Sally'</span>, <span class="hljs-number">9000</span>], [<span class="hljs-number">3</span>,<span class="hljs-string">'Scott'</span>, <span class="hljs-number">20</span>]], columns=[<span class="hljs-string">'id'</span>,<span class="hljs-string">'name'</span>, <span class="hljs-string">'power level'</span>]) df.append(df.sum(axis=<span class="hljs-number">0</span>), ignore_index=<span class="hljs-literal">True</span>) |

Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0).
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
|
1 2 3 4 |
df1 = anime[<span class="hljs-number">0</span>:<span class="hljs-number">2</span>] df2 = anime[<span class="hljs-number">2</span>:<span class="hljs-number">4</span>] pd.concat([df1, df2], ignore_index=<span class="hljs-literal">True</span>) |

Датафрейм df1

Датафрейм df2

Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция df.merge, которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.
|
1 2 |
rating.merge(anime, left_on=’anime_id’, right_on=’anime_id’, suffixes=(‘_left’, ‘_right’)) |

Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
|
1 2 |
anime_modified.loc[[<span class="hljs-string">'Haikyuu!! Second Season'</span>,<span class="hljs-string">'Gintama'</span>]] |

Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции df.iloc первой строке назначается индекс 0, второй — индекс 1, и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.
Следующая конструкция позволяет выбрать три первых строки датафрейма:
|
1 2 |
anime_modified.iloc[<span class="hljs-number">0</span>:<span class="hljs-number">3</span>] |

Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
|
1 2 |
anime[anime[<span class="hljs-string">'type'</span>].isin([<span class="hljs-string">'TV'</span>, <span class="hljs-string">'Movie'</span>])] |

Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
|
1 2 |
anime[anime[‘type’] == <span class="hljs-string">'TV'</span>] |
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
|
1 2 |
anime[<span class="hljs-number">1</span>:<span class="hljs-number">3</span>] |

Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
|
1 2 |
anime[anime[<span class="hljs-string">'rating'</span>] > <span class="hljs-number">8</span>] |

Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values:
|
1 2 |
anime.sort_values(<span class="hljs-string">'rating'</span>, ascending=<span class="hljs-literal">False</span>) |

Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
|
1 2 |
anime.groupby(<span class="hljs-string">'type'</span>).count() |

Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется reset_index(). В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.
|
1 2 3 4 5 6 |
anime.groupby([<span class="hljs-string">"type"</span>]).agg({ <span class="hljs-string">"rating"</span>: <span class="hljs-string">"sum"</span>, <span class="hljs-string">"episodes"</span>: <span class="hljs-string">"count"</span>, <span class="hljs-string">"name"</span>: <span class="hljs-string">"last"</span> }).reset_index() |
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
|
1 2 3 4 5 6 7 |
tmp_df = rating.copy() tmp_df.sort_values(<span class="hljs-string">'user_id'</span>, ascending=<span class="hljs-literal">True</span>, inplace=<span class="hljs-literal">True</span>) tmp_df = tmp_df[tmp_df.user_id < <span class="hljs-number">10</span>] tmp_df = tmp_df[tmp_df.anime_id < <span class="hljs-number">30</span>] tmp_df = tmp_df[tmp_df.rating != <span class="hljs-number">-1</span>] pd.pivot_table(tmp_df, values=<span class="hljs-string">'rating'</span>, index=[<span class="hljs-string">'user_id'</span>], columns=[<span class="hljs-string">'anime_id'</span>], aggfunc=np.sum, fill_value=<span class="hljs-number">0</span>) |

Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения 0 в ячейки, содержащие значение NaN. В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0. А затем используем функцию fillna(0) для замены значений NaN на 0.
|
1 2 3 |
pivot = pd.pivot_table(tmp_df, values=<span class="hljs-string">'rating'</span>, index=[<span class="hljs-string">'user_id'</span>], columns=[<span class="hljs-string">'anime_id'</span>], aggfunc=np.sum) pivot.fillna(<span class="hljs-number">0</span>) |

Таблица, содержащая значения NaN

Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1, то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.
|
1 2 |
anime.sample(frac=<span class="hljs-number">0.25</span>) |

Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
|
1 2 3 |
<span class="hljs-keyword">for</span> idx,row <span class="hljs-keyword">in</span> anime[:<span class="hljs-number">2</span>].iterrows(): print(idx, row) |

Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
|
1 |
jupyter notebook — NotebookApp.iopub_data_rate_limit=<span class="hljs-number">1.0e10</span> |
Сводные таблицы в pandas
Термин “сводная таблица” хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
|
1 2 3 |
<span class="hljs-meta">>>> </span>titanic_df = pd.read_csv(<span class="hljs-string">'titanic.csv'</span>) <span class="hljs-meta">>>> </span>pvt = titanic_df.pivot_table(index=[<span class="hljs-string">'Sex'</span>], columns=[<span class="hljs-string">'PClass'</span>], values=<span class="hljs-string">'Name'</span>, aggfunc=<span class="hljs-string">'count'</span>) |
В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
|
1 2 3 4 5 6 7 |
<span class="hljs-meta">>>> </span>print(pvt.loc[<span class="hljs-string">'female'</span>, [<span class="hljs-string">'1st'</span>, <span class="hljs-string">'2nd'</span>, <span class="hljs-string">'3rd'</span>]]) PClass <span class="hljs-number">1</span>st <span class="hljs-number">143.0</span> <span class="hljs-number">2</span>nd <span class="hljs-number">107.0</span> <span class="hljs-number">3</span>rd <span class="hljs-number">212.0</span> Name: female, dtype: float64 |
Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<span class="hljs-meta">>>> </span><span class="hljs-keyword">import</span> pandas <span class="hljs-keyword">as</span> pd <span class="hljs-meta">>>> </span>df = pd.read_csv(<span class="hljs-string">'apple.csv'</span>, index_col=<span class="hljs-string">'Date'</span>, parse_dates=<span class="hljs-keyword">True</span>) <span class="hljs-meta">>>> </span>df = df.sort_index() <span class="hljs-meta">>>> </span>print(df.info()) <<span class="hljs-class"><span class="hljs-keyword">class</span> '<span class="hljs-title">pandas</span>.<span class="hljs-title">core</span>.<span class="hljs-title">frame</span>.<span class="hljs-title">DataFrame</span>'> <span class="hljs-title">DatetimeIndex</span>:</span> <span class="hljs-number">1258</span> entries, <span class="hljs-number">2017</span><span class="hljs-number">-02</span><span class="hljs-number">-22</span> to <span class="hljs-number">2012</span><span class="hljs-number">-02</span><span class="hljs-number">-23</span> Data columns (total <span class="hljs-number">6</span> columns): Open <span class="hljs-number">1258</span> non-null float64 High <span class="hljs-number">1258</span> non-null float64 Low <span class="hljs-number">1258</span> non-null float64 Close <span class="hljs-number">1258</span> non-null float64 Volume <span class="hljs-number">1258</span> non-null int64 Adj Close <span class="hljs-number">1258</span> non-null float64 dtypes: float64(<span class="hljs-number">5</span>), int64(<span class="hljs-number">1</span>) memory usage: <span class="hljs-number">68.8</span> KB |
Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
|
1 2 3 |
<span class="hljs-meta">>>> </span>df.loc[<span class="hljs-string">'2012-Feb'</span>, <span class="hljs-string">'Close'</span>].mean() <span class="hljs-number">528.4820021999999</span> |
А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
|
1 2 |
<span class="hljs-meta">>>> </span>df.loc[<span class="hljs-string">'2012-Feb'</span>:<span class="hljs-string">'2015-Feb'</span>, <span class="hljs-string">'Close'</span>].mean() <span class="hljs-number">430.43968317018414</span> |
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
|
1 2 3 4 5 |
>>> import matplotlib.pyplot as plt >>> new_sample_df = df.loc['2012-Feb':'2017-Feb', ['Close']] >>> new_sample_df.plot() >>> plt.show() |
И видим вот такую картину:
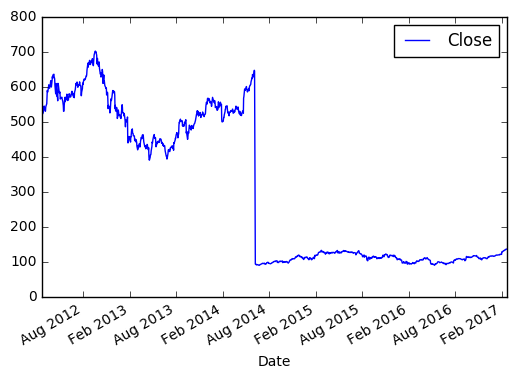
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉